content type paperpublished July 2025
Distillation Scaling Laws
AuthorsDan Busbridge, Amitis Shidani†‡, Floris Weers, Jason Ramapuram, Etai Littwin, Russ Webb
Distillation Scaling Laws
AuthorsDan Busbridge, Amitis Shidani†‡, Floris Weers, Jason Ramapuram, Etai Littwin, Russ Webb
We propose a distillation scaling law that estimates distilled model performance based on a compute budget and its allocation between the student and teacher. Our findings mitigate the risks associated with large-scale distillation by enabling compute-optimal allocation for both the teacher and student to maximize student performance. We provide compute-optimal distillation recipes for two key scenarios: when a teacher already exists, and when a teacher needs training. In settings involving many students or an existing teacher, distillation outperforms supervised learning up to a compute level that scales predictably with student size. Conversely, if only one student is to be distilled and a teacher also requires training, supervised learning is generally preferable. Additionally, our large-scale study of distillation increases our understanding of the process and helps inform experimental design.
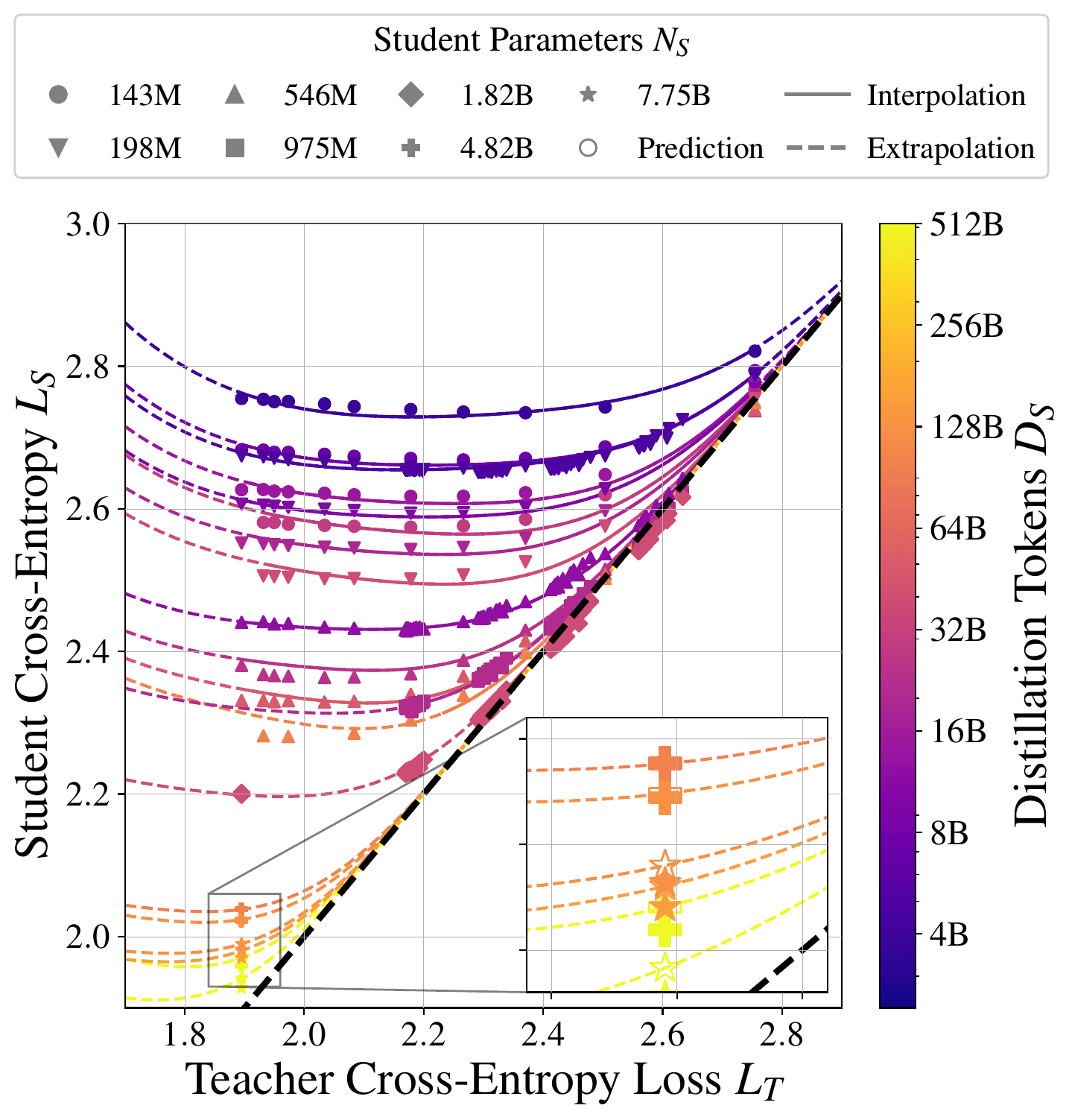
Figure 1: The distillation scaling law is fitted to students with high cross-entropy for a range of teachers with cross-entropies (x-axis). Solid lines represent predicted model behavior for unseen teachers for a given student configuration (interpolation), and dashed lines represent predicted model behavior beyond seen teachers and for low cross-entropy students (extrapolation). The diagonal block dashed line indicates where student and teacher cross-entropies are equal. Teachers with lower cross-entropy generally produce students with lower cross-entropy, until the capacity gap. As shown, a student can also outperform its teacher.
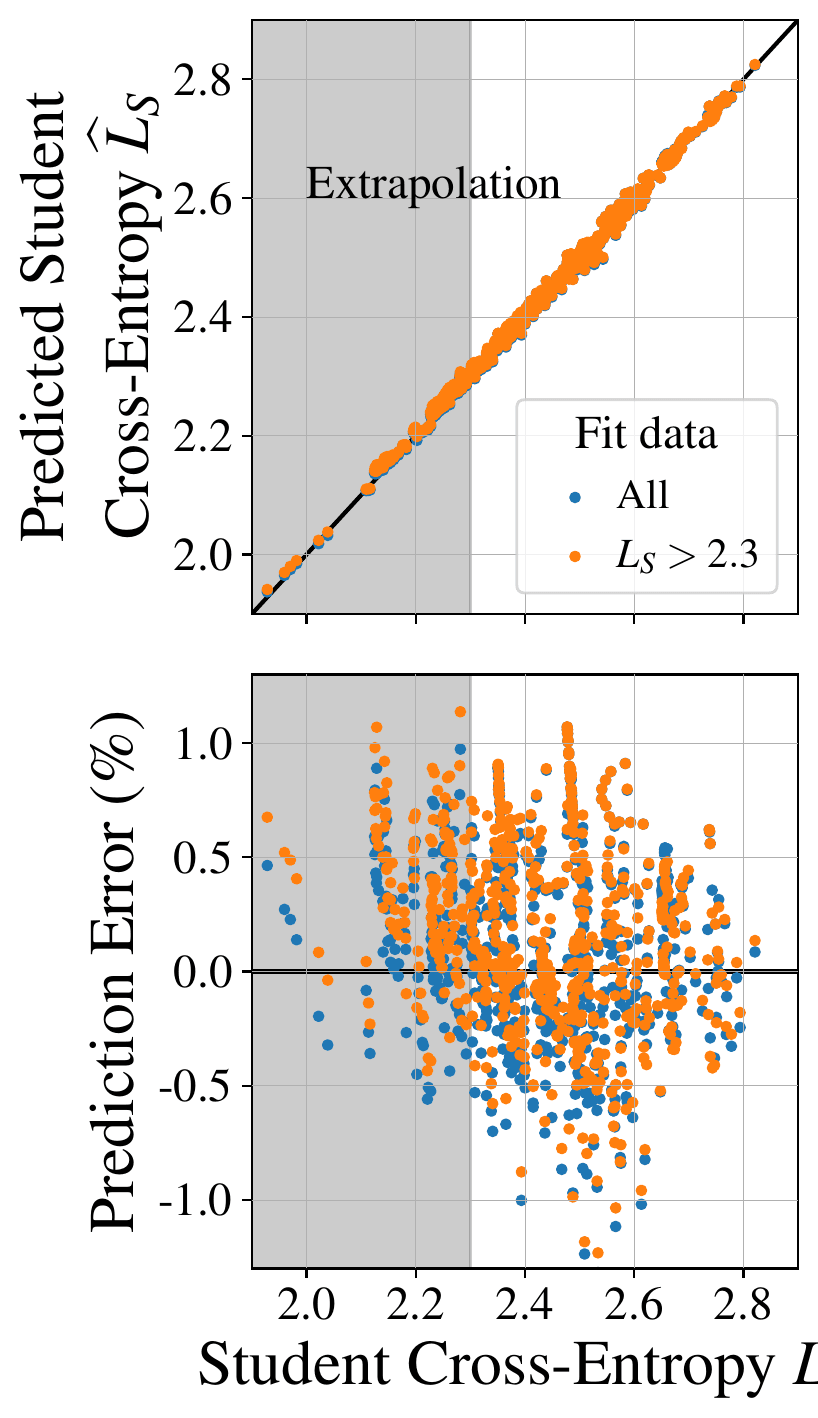
Figure 1: Student cross-entropy predicted by our distillation scaling law compared with the achieved student cross-entropy. Prediction error is at most ~1%.
Unmasking On-Policy Distillation: Where It Helps, Where It Hurts, and Why
July 9, 2026research area Methods and Algorithms, research area Speech and Natural Language Processing
On-policy distillation offers dense, per-token supervision for training reasoning models; however, it remains unclear under which conditions this signal is beneficial and under which it is detrimental. Which teacher model should be used, and in the case of self-distillation, which specific context should serve as the supervisory signal? Does the optimal choice vary from one token to the next? At present, addressing these questions typically…
Rethinking JEPA: Compute-Efficient Video SSL with Frozen Teachers
October 8, 2025research area Computer Vision, research area Methods and Algorithmsconference ICLR
Video Joint Embedding Predictive Architectures (V-JEPA) learn generalizable off-the-shelf video representation by predicting masked regions in latent space with an exponential moving average (EMA)-updated teacher. While EMA prevents representation collapse, it complicates scalable model selection and couples teacher and student architectures. We revisit masked-latent prediction and show that a frozen teacher suffices. Concretely, we (i) train a…

Our research in machine learning breaks new ground every day.