content type paperpublished November 2025
Embedding Atlas: Low-Friction, Interactive Embedding Visualization
AuthorsDonghao Ren, Fred Hohman, Halden Lin, Dominik Moritz
Embedding Atlas: Low-Friction, Interactive Embedding Visualization
AuthorsDonghao Ren, Fred Hohman, Halden Lin, Dominik Moritz
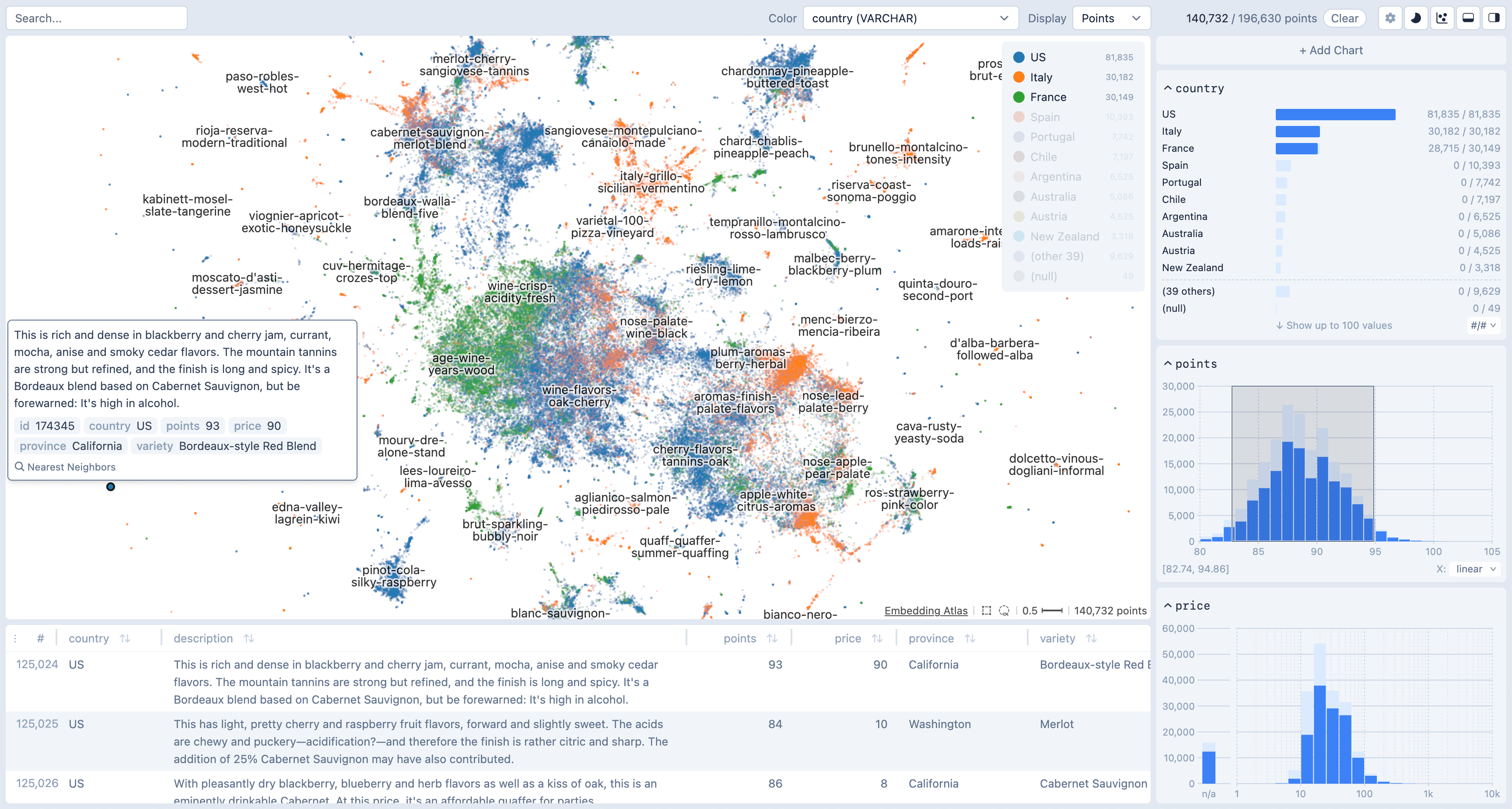
Embedding projections are popular for visualizing large datasets and models. However, people often encounter “friction” when using embedding visualization tools: (1) barriers to adoption, e.g., tedious data wrangling and loading, scalability limits, no integration of results into existing workflows, and (2) limitations in possible analyses, without integration with external tools to additionally show coordinated views of metadata. In this paper, we present Embedding Atlas, a scalable, interactive visualization tool designed to make interacting with large embeddings as easy as possible. Embedding Atlas uses modern web technologies and advanced algorithms — including density-based clustering, and automated labeling — to provide a fast and rich data analysis experience at scale. We evaluate Embedding Atlas with a competitive analysis against other popular embedding tools, showing that Embedding Atlas’s feature set specifically helps reduce friction, and report a benchmark on its real-time rendering performance with millions of points. Embedding Atlas is available as open source to support future work in embedding-based analysis.
Learning Compressed Embeddings for On-Device Inference
March 30, 2022research area Methods and Algorithmsconference MLSys
In deep learning, embeddings are widely used to represent categorical entities such as words, apps, and movies. An embedding layer maps each entity to a unique vector, causing the layer’s memory requirement to be proportional to the number of entities. In the recommendation domain, a given category can have hundreds of thousands of entities, and its embedding layer can take gigabytes of memory. The scale of these networks makes them difficult to…
Single Training Dimension Selection for Word Embedding with PCA
September 30, 2019research area Speech and Natural Language Processingconference EMNLP
In this paper, we present a fast and reliable method based on PCA to select the number of dimensions for word embeddings. First, we train one embedding with a generous upper bound (e.g. 1,000) of dimensions. Then we transform the embeddings using PCA and incrementally remove the lesser dimensions one at a time while recording the embeddings’ performance on language tasks. Lastly, we select the number of dimensions while balancing model size and…

Our research in machine learning breaks new ground every day.