content type paperpublished June 2025
INRFlow: Flow Matching for INRs in Ambient Space
AuthorsYuyang Wang, Anurag Ranjan†, Josh Susskind, Miguel Angel Bautista
INRFlow: Flow Matching for INRs in Ambient Space
AuthorsYuyang Wang, Anurag Ranjan†, Josh Susskind, Miguel Angel Bautista
Flow matching models have emerged as a powerful method for generative modeling on domains like images or videos, and even on irregular or unstructured data like 3D point clouds or even protein structures. These models are commonly trained in two stages: first, a data compressor is trained, and in a subsequent training stage a flow matching generative model is trained in the latent space of the data compressor. This two-stage paradigm sets obstacles for unifying models across data domains, as hand-crafted compressors architectures are used for different data modalities. To this end, we introduce INRFlow, a domain-agnostic approach to learn flow matching transformers directly in ambient space. Drawing inspiration from INRs, we introduce a conditionally independent point-wise training objective that enables INRFlow to make predictions continuously in coordinate space. Our empirical results demonstrate that INRFlow effectively handles different data modalities such as images, 3D point clouds and protein structure data, achieving strong performance in different domains and outperforming comparable approaches. INRFlow is a promising step towards domain-agnostic flow matching generative models that can be trivially adopted in different data domains.
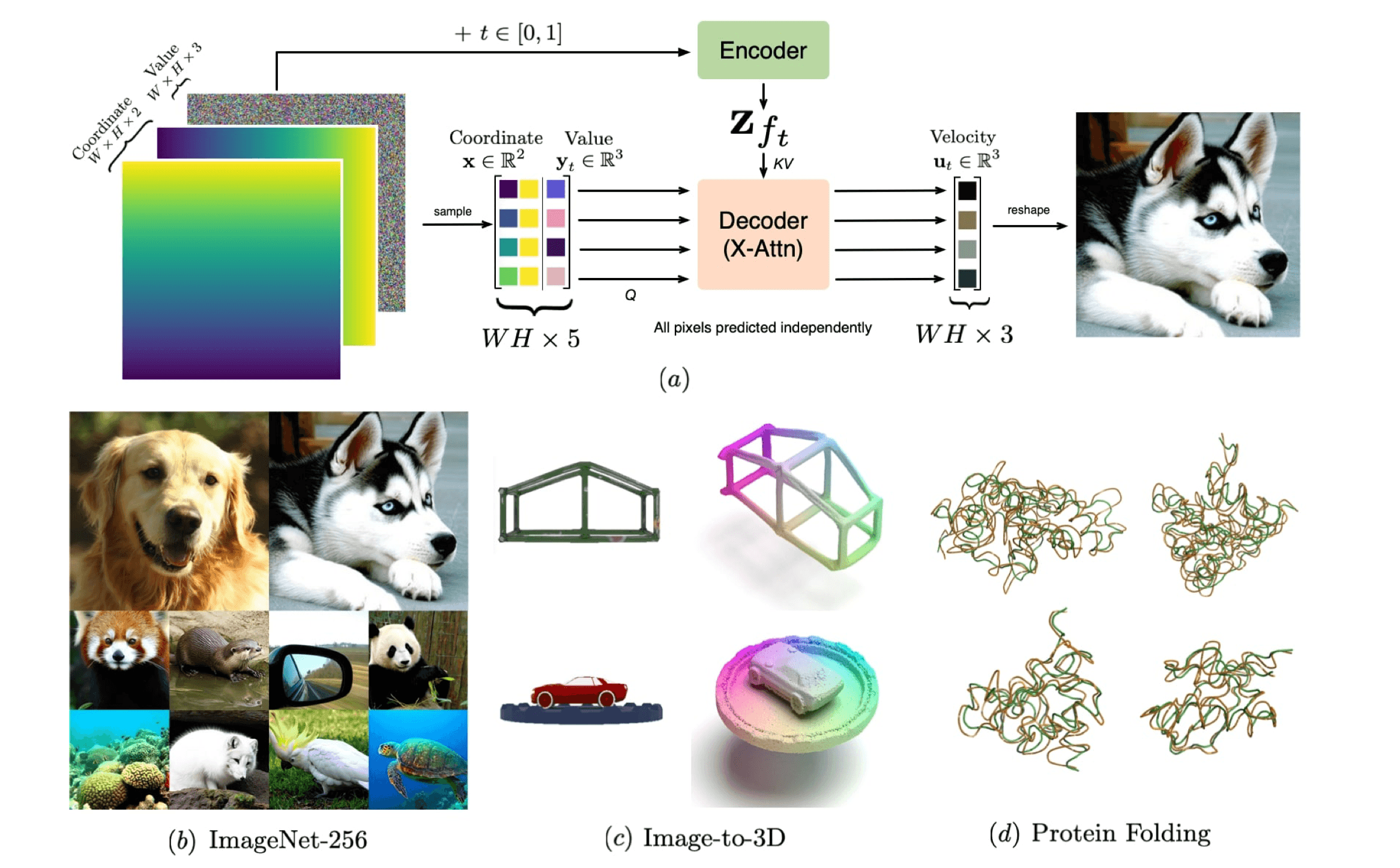
Figure 1: (a) High level overview of INRFlow using the image domain as an example. Our model can be interpreted as an encoder-decoder model where the decoder makes predictions independently for each coordinate-value pair given zft. For different data domains, the coordinate and value dimensionality changes, but the model is kept the same. (b) Samples generated by INRFlow trained on ImageNet 256×256. (c) Image-to-3D point clouds generated by training INRFlow on Objaverse (Deitke et al., 2023). (d) Protein structures generated by INRFlow trained on SwissProt (Boeckmann et al., 2003). GT protein structures are depicted in green while the generated structures by INRFlow are shown in orange.
Score Distillation of Flow Matching Models
December 16, 2025research area Computer Vision, research area Methods and Algorithms
Diffusion models achieve high-quality image generation but are limited by slow iterative sampling. Distillation methods alleviate this by enabling one- or few-step generation. Flow matching, originally introduced as a distinct framework, has since been shown to be theoretically equivalent to diffusion under Gaussian assumptions, raising the question of whether distillation techniques such as score distillation transfer directly. We provide a…
VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
November 13, 2017research area Computer Vision
Accurate detection of objects in 3D point clouds is a central problem in many applications, such as autonomous navigation, housekeeping robots, and augmented/virtual reality. To interface a highly sparse LiDAR point cloud with a region proposal network (RPN), most existing efforts have focused on hand-crafted feature representations, for example, a bird’s eye view projection. In this work, we remove the need of manual feature engineering for 3D…

Our research in machine learning breaks new ground every day.