Apple ML Researcher Hilal Asi guides attendees through his poster presentation on “Private Vector Mean Estimation in the Shuffle Model: Optimal Rates Require Many Messages” at ICML 2024.
Apple ML Researcher Hilal Asi guides attendees through his poster presentation on “Private Vector Mean Estimation in the Shuffle Model: Optimal Rates Require Many Messages” at ICML 2024.
Apple researchers are advancing AI and ML through fundamental research, and to support the broader research community and help accelerate progress in this field, we share much of this research through publications and engagement at conferences. Next week, the International Conference on Machine Learning (ICML) will be held in Vancouver, Canada, and Apple is proud to once again participate in this important event for the research community and to be an industry sponsor.
At the main conference and associated workshops, Apple researchers will present new research across a number of topics in AI and ML, including advances in computer vision, language models, diffusion models, reinforcement learning, and more. A selection of the notable Apple ML research papers accepted at ICML are highlighted below, organized in the following sections:
ICML attendees will be able to experience demonstrations of Apple’s ML research in our booth #307 during exhibition hours. Apple is also sponsoring and participating in a number of affinity group-hosted events that support underrepresented groups in the ML community. A comprehensive overview of Apple’s participation in and contributions to ICML 2025 can be found here, and a selection of highlights papers that will be presented follows below.
Many fields in science and engineering have come to rely on highly complex computer simulations to model real-world phenomena that previously had been modeled with simpler equations. These simulations improve model versatility and the ability to replicate and explain complex phenomena, but they also require new statistical inference methods. Simulation-based inference (SBI) has emerged as the workhorse for inferring the parameters of these stochastic simulators. SBI algorithms use neural networks to learn surrogate models of the likelihood, likelihood ratio, or posterior distribution, which can be used to extract confidence intervals over the parameters of interest given an observation. However, SBI has been shown to be unreliable when the simulator is misspecified.
In an oral presentation at ICML, Apple researchers will share work that addresses this challenge: Addressing Misspecification in Simulation-based Inference through Data-driven Calibration. The paper describes robust posterior estimation (RoPE), a framework that overcomes model misspecification with a small real-world calibration set of ground-truth parameter measurements. The work formalizes the misspecification gap as the solution of an optimal transport (OT) problem between learned representations of real-world and simulated observations, allowing RoPE to learn a model of the misspecification without placing additional assumptions on its nature.
Normalizing Flows (NFs) are likelihood-based models for continuous inputs. This approach has previously shown promising results for density estimation and generative modeling, but NFs have not received much attention for in the research community in recent years, as diffusion models and autoregressive approaches have become the dominant paradigms for image generation.
In an oral presentation at ICML, Apple researchers will share Normalizing Flows are Capable Generative Models, which shows that NFs are more powerful than previously believed and can be used for high-quality image generation. The paper describes TarFlow: a simple and scalable architecture that enables highly performant NF models. TarFlow is a transformer-based variant of Masked Autoregressive Flows (MAFs): it consists of a stack of autoregressive Transformer blocks on image patches, alternating the autoregression direction between layers. Leveraging several techniques to improve sample quality, Tarflow sets new state-of-the-art results on likelihood estimation for images, beating the previous best methods by a large margin, and it can generate samples with quality and diversity comparable to diffusion models - a first for a standalone NF model.
Figure 1: Samples at various resolutions generated by TarFlow.
Being able to build novel compositions at inference time using only the outputs of pretrained models (either entirely separate models, or different conditionings of a single model) could enable generations that are potentially more complex than any model could produce individually. For example, imagine one diffusion model is trained on photos of your dog, and another diffusion model is trained on a collection of oil paintings; if the outputs of these models could be combined, they could be used to generate oil paintings of your dog - despite the fact that those generations would be out-of-distribution (OOD) for both models. Prior empirical work has shown that this ambitious vision is at least partially achievable in practice, but how and why such compositions work has not theoretically explained.
At ICML, Apple researchers will present Mechanisms of Projective Composition of Diffusion Models, a new paper that studies the theoretical foundations of composition in diffusion models, with a particular focus on out-of-distribution extrapolation and length-generalization. The work shares a precise definition of a desired result of composition - projective composition - and provides a theoretical explanation for when and why composing distributions via linear score combination delivers the desired outcome.
Figure 2: Composing diffusion models via score combination. Given two diffusion models, it is sometimes possible to sample in a way that composes content from one model (e.g. your dog) with a style of another model (e.g. oil paintings). The paper, Mechanisms of Projective Composition of Diffusion Models, provides a theoretical explanation of this empirical behavior.
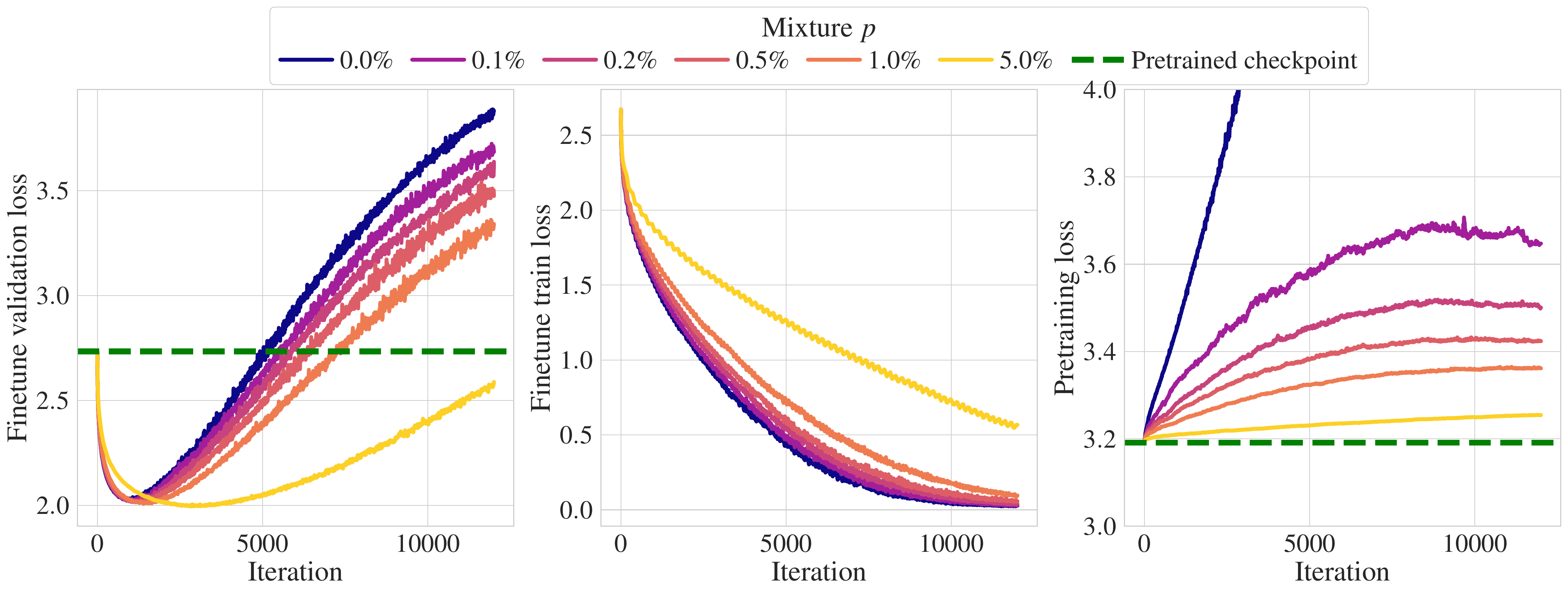
A common approach to get LLMs to perform well in a target domain is to fine-tune them by training them to do unsupervised next-token prediction on data from that domain. However, fine-tuning presents two challenges: i) if the amount of target data is limited (as is the case in most practical applications), the model will quickly overfit, and ii) the model will drift away from the original model and forget the pre-training distribution.
At ICML, Apple researchers will present Scaling Laws for Forgetting During Finetuning with Pretraining Data Injection, which quantifies these two phenomena for several target domains, available target data, and model scales. The work also measures the efficiency of mixing pre-training and target data for fine-tuning to avoid forgetting and mitigate overfitting. A key practical finding in the paper is that including as little as 1% of pre-training data in the fine-tuning data mixture shields a model from forgetting the pre-training set.
Because they are smaller than LLMs, specialist language models are generally more efficient and less expensive, but in many cases, the specialization data - like a company’s internal database, or data on a niche topic - may be too scarce train a good quality small model on its own. As a result, specialist models are commonly trained with large pre-training datasets, by adjusting the mixture of weights of the pre-training distribution to resemble the scarce specialist dataset. However, this requires pre-training a full model for each specialization dataset, which can become impractical when the number of specialized downstream tasks, model size, and data scales.
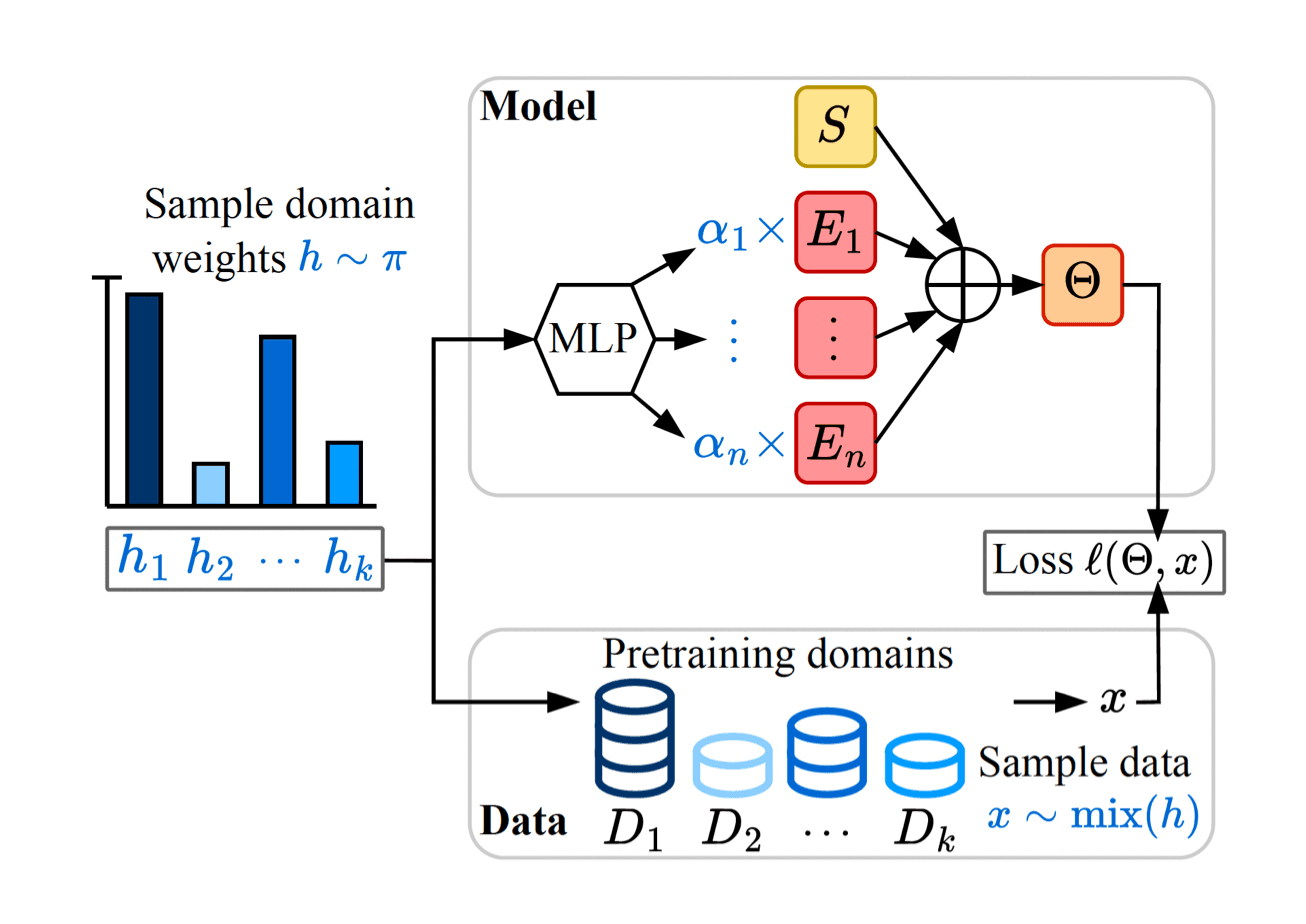
At ICML, Apple researchers will present Soup-of-Experts: Pretraining Specialist Models via Parameters Averaging, which addresses this challenge. The paper details a novel architecture that can instantiate a model at test time for any domain weights with minimal computational cost and without re-training the model. A pre-trained Soup-of-Experts model can instantly instantiate a model tailored to any mixture of domain weights, making this approach particularly well suited for quickly producing many different specialist models under size constraints.
Figure 4: The Soup-of-Experts and its training pipeline. The Soup-of-Experts consists of shared parameters S, nexperts parameters E1,...,En, and an MLP that acts as a routing mechanism. At each optimization step, we sample domain weights h from a meta-distribution π. These domain weights have two purposes: they are passed through an MLP to give a vector of coefficients α that instantiates a model by combining the experts’ weights, and they are used to sample a mini-batch of data following the domain weights law. We then backpropagate through the corresponding loss to update the parameters of the Soup-of-Experts.
Self-play has been an effective strategy for training reinforcement learning (RL) policies for many games, robotic manipulation, and even bio-engineering. At ICML, Apple researchers will share Robust Autonomy Emerges from Self-Play, a research paper showing that this technique can also be a surprisingly effective strategy for learning policies for autonomous driving.
Using GIGAFLOW, a batched simulator architected for self-play RL on a massive scale, the researchers were able to use an unprecedented amount of simulation data - 1.6 billion kilometers of driving. The resulting learned policy achieves state-of-the-art performance on three independent autonomous driving benchmarks, and outperforms the prior state of the art when tested on recorded real-world scenarios, amidst human drivers, despite having never seeing human data during training. The policy is also realistic when assessed against human references and achieves unprecedented robustness, averaging 17.5 years of continuous driving between incidents in simulation.
Figure 5: Overview of GIGAFLOW. a, GIGAFLOW simulates tens of thousands of worlds with millions of agents in a massively parallel self-play reinforcement learning setup. b, Each world tasks agents to navigate to goals on a map without collisions. c, Each agent optimizes its own performance, given a set of local observations. d, All agents use a compact shared policy network.
During exhibition hours, ICML attendees will be able to interact with live demos of Apple ML research in booth #307, including MLX, a flexible array framework that is optimized for Apple silicon. MLX enables training and inference of arbitrarily complex models on Apple silicon powered devices with great brevity and flexibility. At the Apple booth, researchers will showcase fine-tuning a 7B parameter LLM on an iPhone, image generation using a large diffusion model on an iPad, and text generation using a number of LLMs on an M2 Ultra Mac Studio.
Apple is committed to supporting underrepresented groups in the ML community. We are proud to again sponsor several affinity groups hosting events onsite at ICML, including LatinX in AI(workshop on July 14) and Women in Machine Learning (WiML)(workshop on July 16). In addition to supporting these workshops with sponsorship, Apple employees will also be participating at each of these and other affinity events.
ICML brings together the community of researchers advancing the state of the art in ML, and Apple is proud to again share innovative new research at the event and connect with the community attending it. This post highlights just a selection of the works Apple ML researchers will present at ICML 2025, and a comprehensive overview and schedule of our participation can be found here.
Apple researchers advance AI and ML through fundamental research, and to support the broader research community and help accelerate progress in this field, we share much of this work through publications and engagement at conferences.
Apple researchers are advancing the field of ML through fundamental research that improves the world’s understanding of this technology and helps to redefine what is possible with it. This work may lead to advancements in Apple’s products and services, and the benefits of the research extend beyond the Apple ecosystem as it is shared with the broader research community through publication, open source resources, and engagement at industry and…