content type highlightpublished June 8, 2021
Leveraging ML Compute for Accelerated Training on Mac
Leveraging ML Compute for Accelerated Training on Mac
The Mac has long been a popular platform for developers, engineers, and researchers. Now, with Macs powered by the all new M1 chip, and the ML Compute framework available in macOS Big Sur, neural networks can be trained right on the Mac with a huge leap in performance.
Update - You can now leverage Apple’s tensorflow-metal PluggableDevice in TensorFlow v2.5 for accelerated training on Mac GPUs directly with Metal. Get started with: tensorflow-metal.
Until now, TensorFlow has only utilized the CPU for training on Mac. The new tensorflow_macos fork of TensorFlow 2.4 leverages ML Compute to enable machine learning libraries to take full advantage of not only the CPU, but also the GPU in both M1- and Intel-powered Macs for dramatically faster training performance. This starts by applying higher-level optimizations such as fusing layers, selecting the appropriate device type and compiling and executing the graph as primitives that are accelerated by BNNS on the CPU and Metal Performance Shaders on the GPU.
Performance benchmarks for Mac-optimized TensorFlow training show significant speedups for common models across M1- and Intel-powered Macs when leveraging the GPU for training. For example, TensorFlow users can now get up to 7x faster training on the new 13-inch MacBook Pro with M1:
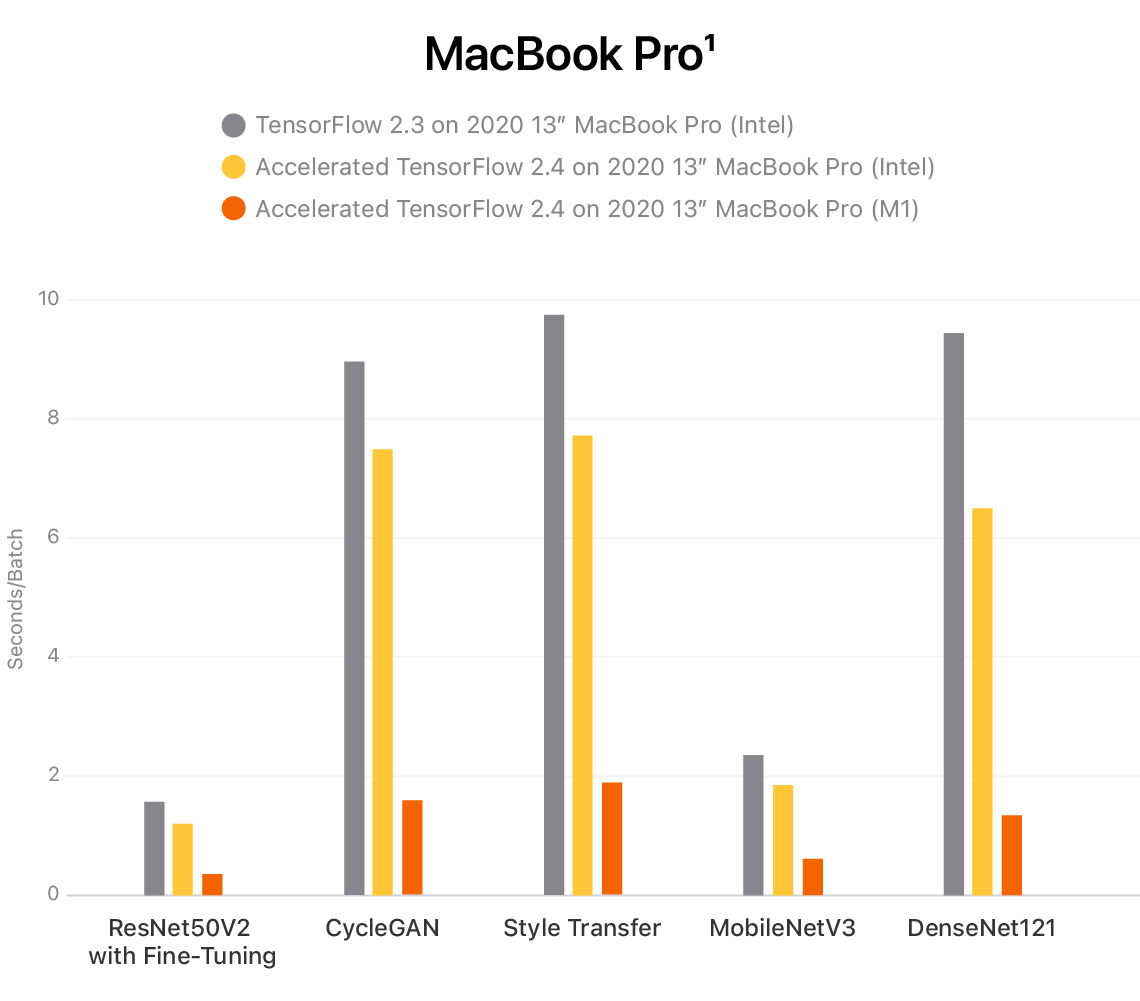
Training impact on common models using ML Compute on M1- and Intel-powered 13-inch MacBook Pro are shown in seconds per batch, with lower numbers indicating faster training time.

Training impact on common models using ML Compute on the Intel-powered 2019 Mac Pro are shown in seconds per batch, with lower numbers indicating faster training time.
To start using Mac-optimized TensorFlow, visit the tensorflow_macos GitHub repository. You can also visit TensorFlow’s blog post to learn more.
Testing conducted by Apple in October and November 2020 using a preproduction 13-inch MacBook Pro system with Apple M1 chip, 16GB of RAM, and 256GB SSD, as well as a production 1.7GHz quad-core Intel Core i7-based 13-inch MacBook Pro system with Intel Iris Plus Graphics 645, 16GB of RAM, and 2TB SSD. Tested with prerelease macOS Big Sur, TensorFlow 2.3, prerelease TensorFlow 2.4, ResNet50V2 with fine-tuning, CycleGAN, Style Transfer, MobileNetV3, and DenseNet121. Performance tests are conducted using specific computer systems and reflect the approximate performance of MacBook Pro.
Testing conducted by Apple in October and November 2020 using a production 3.2GHz 16-core Intel Xeon W-based Mac Pro system with 32GB of RAM, AMD Radeon Pro Vega II Duo graphics with 64GB of HBM2, and 256GB SSD. Tested with prerelease macOS Big Sur, TensorFlow 2.3, prerelease TensorFlow 2.4, ResNet50V2 with fine-tuning, CycleGAN, Style Transfer, MobileNetV3, and DenseNet121. Performance tests are conducted using specific computer systems and reflect the approximate performance of Mac Pro.
Exploring LLMs with MLX and the Neural Accelerators in the M5 GPU
November 19, 2025
Mac with Apple silicon is increasingly popular among AI developers and researchers interested in using their Mac to experiment with the latest models and techniques. With MLX, users can explore and run LLMs efficiently on Mac. It allows researchers to experiment with new inference or fine-tuning techniques, or investigate AI techniques in a private environment, on their own hardware. MLX works with all Apple silicon systems, and with the latest…
NeurIPS 2020
December 2, 2020research area Generalconference NeurIPS
Apple sponsored the Neural Information Processing Systems (NeurIPS) conference, which was held virtually from December 6 to 12. NeurIPS is a global conference focused on fostering the exchange of research on neural information processing systems in their biological, technological, mathematical, and theoretical aspects.

Our research in machine learning breaks new ground every day.