content type highlightpublished April 16, 2018
Personalized Hey Siri
AuthorsSiri Team
Personalized Hey Siri
AuthorsSiri Team
Apple introduced the “Hey Siri” feature with the iPhone 6 (iOS 8). This feature allows users to invoke Siri without having to press the home button. When a user says, “Hey Siri, how is the weather today?” the phone wakes up upon hearing “Hey Siri” and processes the rest of the utterance as a Siri request. The feature’s ability to listen continuously for the “Hey Siri” trigger phrase lets users access Siri in situations where their hands might be otherwise occupied, such as while driving or cooking, as well as in situations when their respective devices are not within arm’s reach. Imagine a scenario where a user is asking his or her iPhone 6 on the kitchen counter to set a timer while putting a turkey into the oven.
On the iPhone 6, the “Hey Siri” feature could only be used when the phone was charging; however, subsequent generations of the iPhone (6S onwards) and iPad used a low-power and always-on processor for continuous listening. As such, the “Hey Siri” feature could be used at any time.
The more general, speaker-independent problem of “Hey Siri” detection is also known as a “key-phrase detection” problem. The technical approach and implementation details of our solution are described in a previously-published Apple Machine Learning Journal article [1]. Here in this work, we assume that the “Hey Siri” detector exists and motivate the need for on-device personalization in the form of a speaker recognition system. We describe our early modeling efforts using deep neural networks and set the stage for the improvements described in a subsequent ICASSP 2018 paper [2], in which we obtain more robust speaker-specific representations using a recurrent neural network, multi-style training, and curriculum learning.
The phrase “Hey Siri” was originally chosen to be as natural as possible; in fact, it was so natural that even before this feature was introduced, users would invoke Siri using the home button and inadvertently prepend their requests with the words, “Hey Siri.” Its brevity and ease of articulation, however, bring to bear additional challenges. In particular, our early offline experiments showed, for a reasonable rate of correctly accepted invocations, an unacceptable number of unintended activations. Unintended activations occur in three scenarios - 1) when the primary user says a similar phrase, 2) when other users say “Hey Siri,” and 3) when other users say a similar phrase. The last one is the most annoying false activation of all. In an effort to reduce such False Accepts (FA), our work aims to personalize each device such that it (for the most part) only wakes up when the primary user says “Hey Siri.” To do so, we leverage techniques from the field of speaker recognition.
The overall goal of speaker recognition (SR) is to ascertain the identity of a person using his or her voice. We are interested in “who is speaking,” as opposed to the problem of speech recognition, which aims to ascertain “what was spoken.” SR performed using a phrase known a priori, such as “Hey Siri,” is often referred to as text-dependent SR; otherwise, the problem is known as text-independent SR.
We measure the performance of a speaker recognition system as a combination of an Imposter Accept (IA) rate and a False Reject (FR) rate. It is important, however, to distinguish (and equate) these values from those used to measure the quality of a key-phrase trigger system. For both the key-phrase trigger system and the speaker recognition system, a False Reject (or Miss) is observed when the target user says “Hey Siri” and his or her device does not wake up. This sort of error tends to occur more often in acoustically noisy environments, such as in a moving car or on a bustling sidewalk. We report FR’s as a fraction of the total number of true “Hey Siri” instances spoken by the target user. For the key-phrase trigger system, a False Accept (or False Alarm, FA) is observed when the device wakes up to a non-”Hey Siri” phrase, such as “are you serious” or “in Syria today.” Typically, FA’s are measured on a per-hour basis.
In the speaker recognition scenario, we assume that all incoming utterances contain the text “Hey Siri.” In particular, this speaker-dependent personalization step occurs after the speaker-independent “Hey Siri” detector has correctly identified a positive trigger. To this end, we refer to speaker recognition-based false alarm errors as imposter accepts (IA) and avoid confusing such errors with non-”Hey Siri” false accept (FA) errors made by the key-phrase trigger system. In practice, of course, the speaker recognition step will have to contend with false accept errors made by the trigger system. While its effectiveness is impressive, this is not yet something we actually train our system to handle; we discuss this issue a bit later. Lastly, a chosen operating point, or a set of decision thresholds, will affect the FA, FR, and IA rates; higher thresholds reduce FA’s and IA’s at the cost of increasing FR’s, and vice versa.
The application of a speaker recognition system involves a two-step process: enrollment and recognition. During the enrollment phase, the user is asked to say a few sample phrases. These phrases are used to create a statistical model for the users’s voice. In the recognition phase, the system compares an incoming utterance to the user-trained model and decides whether to accept that utterance as belonging to the existing model or reject it.
The main design discussion for personalized “Hey Siri” (PHS) revolves around two methods for user enrollment: explicit and implicit. During explicit enrollment, a user is asked to say the target trigger phrase a few times, and the on-device speaker recognition system trains a PHS speaker profile from these utterances. This ensures that every user has a faithfully-trained PHS profile before he or she begins using the “Hey Siri” feature; thus immediately reducing IA rates. However, the recordings typically obtained during the explicit enrollment often contain very little environmental variability. This initial profile is usually created using clean speech, but real-world situations are almost never so ideal.
This brings to bear the notion of implicit enrollment, in which a speaker profile is created over a period of time using the utterances spoken by the primary user. Because these recordings are made in real-world situations, they have the potential to improve the robustness of our speaker profile. The danger, however, lies in the handling of imposter accepts and false alarms; if enough of these get included early on, the resulting profile will be corrupted and not faithfully represent the primary users’ voice. The device might begin to falsely reject the primary user’s voice or falsely accept other imposters’ voices (or both!) and the feature will become useless.
Our current implementation combines the two enrollment steps. It initializes a speaker profile using the explicit enrollment. The five explicit enrollment phrases requested from the user are, in order:
1. “Hey Siri”
2. “Hey Siri”
3. “Hey Siri”
4. “Hey Siri, how is the weather today?”
5. “Hey Siri, it’s me.”
This variety of utterances also helps to inform users of the different ways in which this feature can be utilized (1-shot and 2-shot mode), and everyone can begin using this feature at a controlled and manageable FA rate.
In the next section, we describe how we implicitly update the speaker profile with subsequently accepted utterances. Looking even further ahead, we imagine a future without any explicit enrollment step in which users simply begin using the “Hey Siri” feature from an empty profile, which then grows and updates organically as more “Hey Siri” requests come in. This would also make things easier for the users who chose to skip the initial “Hey Siri” explicit enrollment setup.
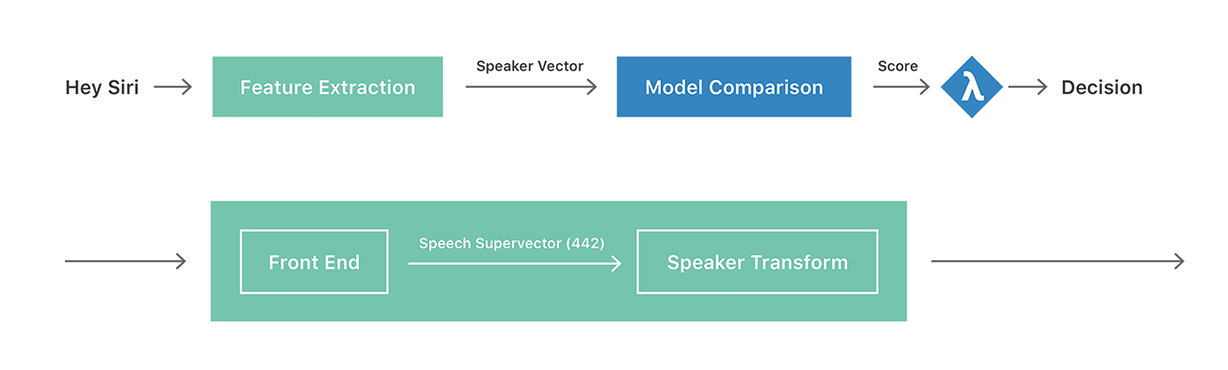
The top half of Figure 1 shows a high-level diagram of our PHS system. The block shown in green, Feature Extraction, converts an acoustic instance of “Hey Siri,” which can vary in duration, into a fixed-length speaker vector. This vector can also be referred to as a speaker embedding. Within the Feature Extraction block, we compute a speaker vector in two steps, as shown in the expanded version of the block at the bottom half of Figure 1. The first step converts the incoming speech utterance to a fixed-length speech (super)vector, which can be seen as a summary of the acoustic information present in the “Hey Siri” utterance; this includes information about the phonetic content, the background recording environment, and the identity of the speaker. In the second step, we attempt to transform the speech vector in a way that focuses on speaker-specific characteristics and deemphasizes variabilities attributed to phonetic and environmental factors. Ideally, this transformation can be trained to recognize a user’s instances of “Hey Siri” in varying environments (e.g., kitchen, car, cafe, etc.) and modes of vocalization (e.g., groggy morning voice, normal voice, raised voice, etc.). Our output is then a low-dimensional representation of speaker information, hence a speaker vector.
On each “Hey Siri”-enabled device, we store a user profile consisting of a collection of speaker vectors. As previously discussed, the profile contains five vectors after the explicit enrollment process. In the Model Comparison stage of Figure 1, we extract a corresponding speaker vector for every incoming test utterance and compute its cosine score (i.e., a length-normalized dot product) against each of the speaker vectors currently in the profile. If the average of these scores is greater than a pre-determined threshold (), then the device wakes up and processes the subsequent command. Lastly, as part of the implicit enrollment process, we add the latest accepted speaker vector to the user profile until it contains 40.
In addition to the speaker vectors, we also store on the phone the “Hey Siri” portion of their corresponding utterance waveforms. When improved transforms are deployed via an over-the-air update, each user profile can then be rebuilt using the stored audio.
The speaker transform is the most important part of any speaker recognition system. Given a speech vector, the goal of this transform is to minimize within-speaker variability while maximizing between-speaker variability. In our initial approach, we derived our speech vector from the speaker-independent “Hey Siri” detector [1], which uses 13-dimensional Mel frequency cepstral coefficients (MFCCs) as acoustic features and parameterizes 28 HMM states to model a “Hey Siri” utterance. The speech vector is then obtained by concatenating the state segment means into a 28 * 13 = 364-dimensional vector.
This approach closely resembles existing work in the research field, where one of the state-of-the-art approaches also uses concatenated acoustic state segment means as its initial representation of the speech in the utterance. (Aside: in speaker recognition parlance, this is known as a “supervector,” as it is a concatenation of other vectors. Another well-known representation is the “i-vector,” which can be seen as a low-dimensional representation of the supervector that captures the directions of maximal variability [3]; i.e., similar to Principal Components Analysis. While i-vectors achieved major success on the text-independent speaker recognition problem, we found speech supervectors to be similarly effective in our text-dependent scenario.) The goal, then, is to find some subspace of this representation that can serve as a reliable speaker representation.
Following that of previous work, the first version of our speaker transform was trained via Linear Discriminant Analysis (LDA) using data from 800 production users with more than 100 utterances each and produced a 150-dimensional speaker vector. Despite its relative simplicity, this initial version significantly reduced our FA rate relative to a no-speaker-transform baseline.
The transform was further improved by using explicit enrollment data, enhancing the front-end speech vector, and switching to a non-linear discriminative technique in the form of deep neural networks (DNNs). Adhering to the knowledge in the speaker recognition research community that higher order cepstral coefficients can capture more speaker-specific information, we increased the number of MFCCs used to 26 from 13. Furthermore, because the first 11 HMM states effectively just model silence, we removed them from consideration. This yielded a new speech vector containing 26 * 17 = 442 dimensions. We then trained a DNN from 16,000 users each speaking ~150 utterances. The network architecture consisted of a 100-neuron hidden layer with a sigmoid activation (i.e., 1x100S) followed by a 100-neuron hidden layer with a linear activation, and a softmax layer with 16000 output nodes. The network is trained using the speech vector as an input and the corresponding 1-hot vector for each speaker as a target. After the DNN is trained, the last layer (softmax) is removed and the output of the linear activation layer is used as a speaker vector. This process is shown in Figure 2.

In our hyperparameter optimization experiments, we found that a network architecture of four 256-neuron layers with sigmoid activations (i.e., 4x256S) followed by the 100-neuron linear layer obtained the best results. We compensate for the additional memory required to accommodate the larger network’s increase in number of parameters by applying 8-bit quantization to the weights in each layer.
In addition to FR and IA rates, we can also summarize the performance of a speaker recognition system via a single equal error rate (EER) value; this is the point at which FR is equal to IA. In the absence of a desired operating point, which can include the cost of different errors and/or the prior probability of a target vs. impostor test utterance, the EER tends to be a good indicator of overall performance.
| EER (%) | |
|---|---|
| Retrained linear transform | 8.0 |
| 1x100S DNN | 5.3 |
| 4x256S DNN | 4.3 |
| FA | %FR | %IA | |
|---|---|---|---|
| Retrained linear transform | 2 per mont | 9.8 | 11.9 |
| 1x100S DNN | 1 per month | 5.9 | 3.1 |
| 4x256S DNN | 1 per month | 5.2 | 3.2 |
Table 1 shows the EER’s obtained using the three different speaker transforms described above. The experiment is performed using 200 randomly selected users from production data. The average pitch of the users varies uniformly from 75 Hz to 250 Hz. The first two rows of Table 1a show that speaker recognition performance improves noticeably with an improved front end (speech vector) and the non-linear modeling brought on by a neural network (speaker vectors), while the third row demonstrates the power of a larger network. These results are corroborated by an independent investigation conducted in [4], in which the authors explored similar approaches on a different dataset and obtained analogous performance improvements.
Because the EER is measured only on a speaker recognition task where the input audio is assumed to contain instances of “Hey Siri,” the observed improvement does not necessarily guarantee a performance improvement on the end-to-end “Hey Siri” application. Table 1b shows the FA, FR, and IA rates of the complete feature using various speaker transforms. The experiment is performed using 2800 hours of negative (non-trigger) data from podcasts and other sources, as well as positive trigger data from 150 male and female users. Our results seem to suggest that an improved DNN speaker transform significantly improves the overall “Hey Siri” feature performance.
Although the average speaker recognition performance has improved significantly, anecdotal evidence suggests that the performance in reverberant (large room) and noisy (car, wind) environments still remain more challenging. One of our current research efforts is focused on understanding and quantifying the degradation in these difficult conditions in which the environment of an incoming test utterance is a severe mismatch from the existing utterances in a user’s speaker profile. In our subsequent work [2], we demonstrate success in the form of multi-style training, in which a subset of the training data is augmented with different types of noise and reverberation.
At its core, the purpose of the “Hey Siri” feature is to enable users to make Siri requests. The work described in this paper utilizes only the trigger phrase (i.e., “Hey Siri”) portion of the utterance for speaker recognition; however, we can also make use of the Siri request portion of the utterance (e.g., ”…, how’s the weather today?”) in the form of text-independent speaker recognition. In [2], we investigate the use of curriculum learning with a recurrent neural network architecture (specifically LSTMs [5]) to summarize speaker information from variable-length audio sequences containing both text-dependent and text-independent information. Our results along these lines show that significant improvements in performance can be achieved by using the complete “Hey Siri, …” utterance for speaker recognition.
[1] Siri Team. Hey Siri: An On-device DNN-powered Voice Trigger for Apple’s Personal Assistant, Apple Machine Learning Research
[2] E. Marchi, S. Shum, K. Hwang, S. Kajarekar, S. Sigtia, H. Richards, R. Haynes, Y. Kim, and J. Bridle. Generalised Discriminative Transform via Curriculum Learning for Speaker Recognition. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), April 2018.
[3] N. Dehak, P. Kenny, R. Dehak, P. Dumouchel, and P. Ouellet. Front-end Factor Analysis for Speaker Verification. IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 4, pp. 788-798, May 2011.
[4] G. Bhattacharya, J. Alam, P. Kenny, and V. Gupta. Modelling Speaker and Channel Variability Using Deep Neural Networks for Robust Speaker Verification. Proceedings of the IEEE Workshop on Spoken Language Technology (SLT), December 2016.
[5] G. Heigold, I. Moreno, S. Bengio, and N. Shazeer. End-to-end Text-dependent Speaker Verification. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), March 2016.
A growing number of consumer devices, including smart speakers, headphones, and watches, use speech as the primary means of user input. As a result, voice trigger detection systems—a mechanism that uses voice recognition technology to control access to a particular device or feature—have become an important component of the user interaction pipeline as they signal the start of an interaction between the user and a device. Since these systems are deployed entirely on-device, several considerations inform their design, like privacy, latency, accuracy, and power consumption.
Hey Siri: An On-device DNN-powered Voice Trigger for Apple’s Personal Assistant
October 1, 2017research area Speech and Natural Language Processing
The “Hey Siri” feature allows users to invoke Siri hands-free. A very small speech recognizer runs all the time and listens for just those two words. When it detects “Hey Siri”, the rest of Siri parses the following speech as a command or query. The “Hey Siri” detector uses a Deep Neural Network (DNN) to convert the acoustic pattern of your voice at each instant into a probability distribution over speech sounds. It then uses a temporal integration process to compute a confidence score that the phrase you uttered was “Hey Siri”. If the score is high enough, Siri wakes up. This article takes a look at the underlying technology. It is aimed primarily at readers who know something of machine learning but less about speech recognition.

Our research in machine learning breaks new ground every day.