content type paperpublished August 2025
Your LLM Knows the Future: Uncovering Its Multi-Token Prediction Potential
AuthorsMohammad Samragh*, Arnav Kundu*, David Harrison*, Kumari Nishu, Devang Naik, Minsik Cho, Mehrdad Farajtabar
Your LLM Knows the Future: Uncovering Its Multi-Token Prediction Potential
AuthorsMohammad Samragh*, Arnav Kundu*, David Harrison*, Kumari Nishu, Devang Naik, Minsik Cho, Mehrdad Farajtabar
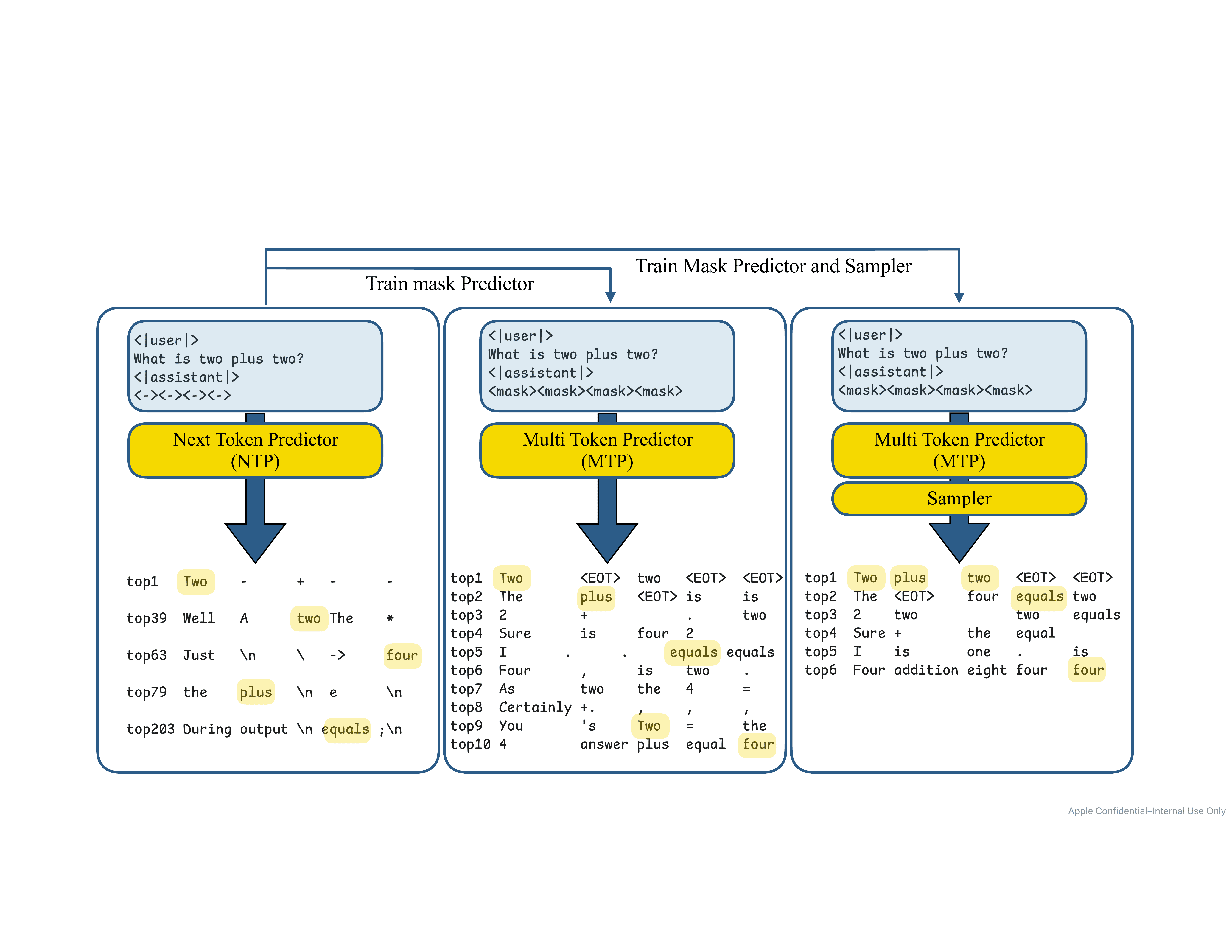
Autoregressive language models are constrained by their inherently sequential nature, generating one token at a time. This paradigm limits inference speed and parallelism, especially during later stages of generation when the direction and semantics of text are relatively certain. In this work, we propose a novel framework that leverages the inherent knowledge of vanilla autoregressive language models about future tokens, combining techniques to realize this potential and enable simultaneous prediction of multiple subsequent tokens. Our approach introduces several key innovations: (1) a masked-input formulation where multiple future tokens are jointly predicted from a common prefix; (2) a gated LoRA formulation that preserves the original LLM’s functionality, while equipping it for multi-token prediction; (3) a lightweight, learnable sampler module that generates coherent sequences from the predicted future tokens; (4) a set of auxiliary training losses, including a consistency loss, to enhance the coherence and accuracy of jointly generated tokens; and (5) a speculative generation strategy that expands tokens quadratically in the future while maintaining high fidelity. Our method achieves significant speedups through supervised fine-tuning on pretrained models. For example, it generates code and math nearly 5x faster, and improves general chat and knowledge tasks by almost 2.5x. These gains come without any loss in quality.
VideoFlexTok: Flexible-Length Coarse-to-Fine Video Tokenization
July 2, 2026research area Computer Visionconference ICML
Visual tokenizers map high-dimensional raw pixels into a compressed representation for downstream modeling. Beyond compression, tokenizers dictate what information is preserved and how it is organized. A de facto standard approach to video tokenization is to represent a video as a spatiotemporal 3D grid of tokens, each capturing the corresponding local information in the original signal. This requires the downstream model that consumes the…
FlexTok: Resampling Images into 1D Token Sequences of Flexible Length
February 19, 2025research area Computer Vision
This work was done in collaboration with Swiss Federal Institute of Technology Lausanne (EPFL).
Image tokenization has enabled major advances in autoregressive image generation by providing compressed, discrete representations that are more efficient to process than raw pixels. While traditional approaches use 2D grid tokenization, recent methods like TiTok have shown that 1D tokenization can achieve high generation quality by eliminating grid…

Our research in machine learning breaks new ground every day.