We present RelCon, a novel self-supervised Relative Contrastive learning approach for training a motion foundation model from wearable accelerometry sensors. First, a learnable distance measure is trained to capture motif similarity and domain-specific semantic information such as rotation invariance. Then, the learned distance provides a measurement of semantic similarity between a pair of accelerometry time-series, which we use to train our foundation model to model relative relationships across time and across subjects. The foundation model is trained on 1 billion segments from 87,376 participants, and achieves state-of- the-art performance across multiple downstream tasks, including human activity recognition and gait metric regression. To our knowledge, we are the first to show the generalizability of a foundation model with motion data from wearables across distinct evaluation tasks.
† University of Illinois Urbana-Champaign (UIUC)
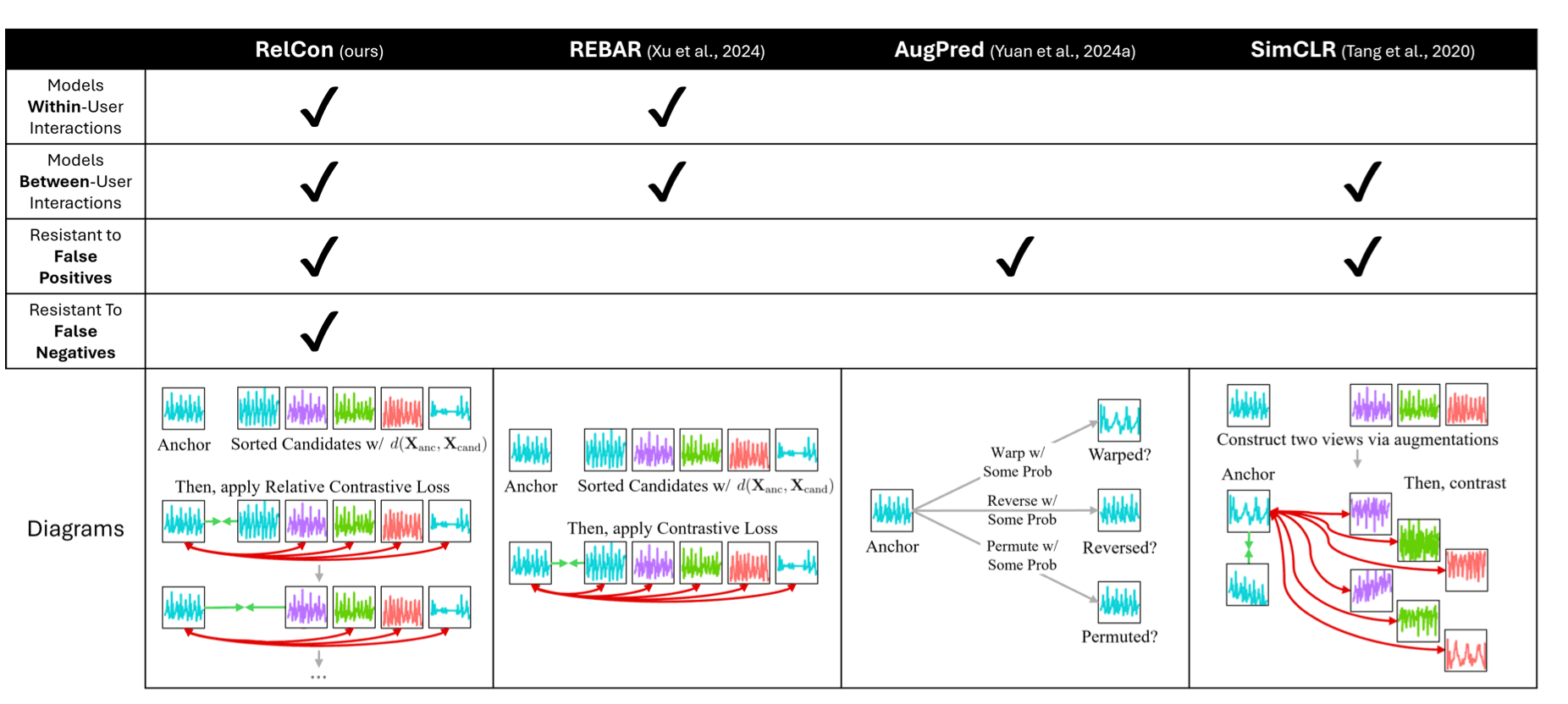
Figure 1: Each sequence color represents a different user’s time-series. RelCon draws candidates from both within- and between-user and ranks them by their relative similarity via a learnable distance function. Then, it iteratively applies a contrastive loss, selecting one candidate as positive while assigning the more distant as negative. This helps prevent false positives/negatives because the full relative ranking is captured. Prior approaches define a single positive/negative set, risking semantic errors if misdefined. AugPred and SimCLR construct positive pairs via semantics-preserving augmentations and thus are resistant to false positives, but REBAR does not have a semantically-constrained pair construction. Furthermore, each method’s candidate sampling varies, affecting their modeling of within- and between-user interactions.