content type paperpublished July 2025
Soup-of-Experts: Pretraining Specialist Models via Parameters Averaging
AuthorsPierre Ablin, Angelos Katharopoulos, Skyler Seto, David Grangier
Soup-of-Experts: Pretraining Specialist Models via Parameters Averaging
AuthorsPierre Ablin, Angelos Katharopoulos, Skyler Seto, David Grangier
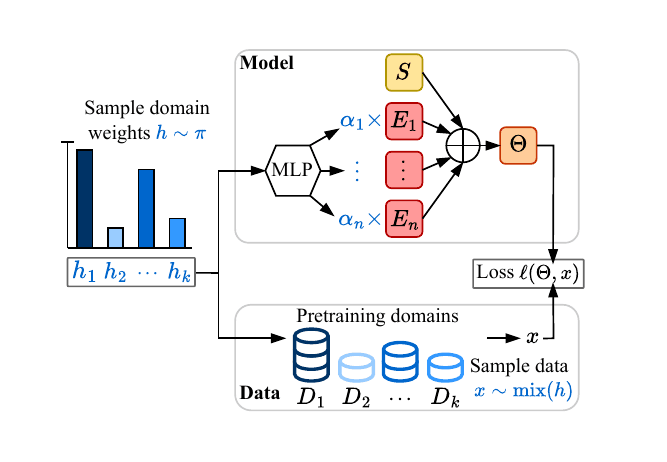
Large-scale models are routinely trained on a mixture of different data sources. Different data mixtures yield very different downstream performances. We propose a novel architecture that can instantiate one model for each data mixture without having to re-train the model. Our architecture consists of a bank of expert weights, which are linearly combined to instantiate one model. We learn the linear combination coefficients as a function of the input histogram. To train this architecture, we sample random histograms, instantiate the corresponding model, and backprop through one batch of data sampled from the corresponding histogram. We demonstrate the promise of our approach to quickly obtain small specialized models on several datasets.
MixAtlas: Uncertainty-aware Data Mixture Optimization for Multimodal LLM Midtraining
April 16, 2026research area Computer Vision, research area Methods and AlgorithmsWorkshop at ICLR
This paper was accepted at the Workshop on Navigating and Addressing Data Problems for Foundation Models (NADPFM) at ICLR 2026.
Principled domain reweighting can substantially improve sample efficiency and downstream generalization; however, data-mixture optimization for multimodal pretraining remains underexplored. Current multimodal training recipes tune mixtures from only a single perspective such as data format or task type. We introduce…
Scaling Laws for Optimal Data Mixtures
September 26, 2025research area Methods and Algorithmsconference NeurIPS
Large foundation models are typically trained on data from multiple domains, with the data mixture—the proportion of each domain used—playing a critical role in model performance. The standard approach to selecting this mixture relies on trial and error, which becomes impractical for large-scale pretraining. We propose a systematic method to determine the optimal data mixture for any target domain using scaling laws. Our approach…

Our research in machine learning breaks new ground every day.