content type paperpublished July 2025
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video
AuthorsRyan Hoque*, Peide Huang*, David J. Yoon*, Mouli Sivapurapu, Jian Zhang
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video
AuthorsRyan Hoque*, Peide Huang*, David J. Yoon*, Mouli Sivapurapu, Jian Zhang
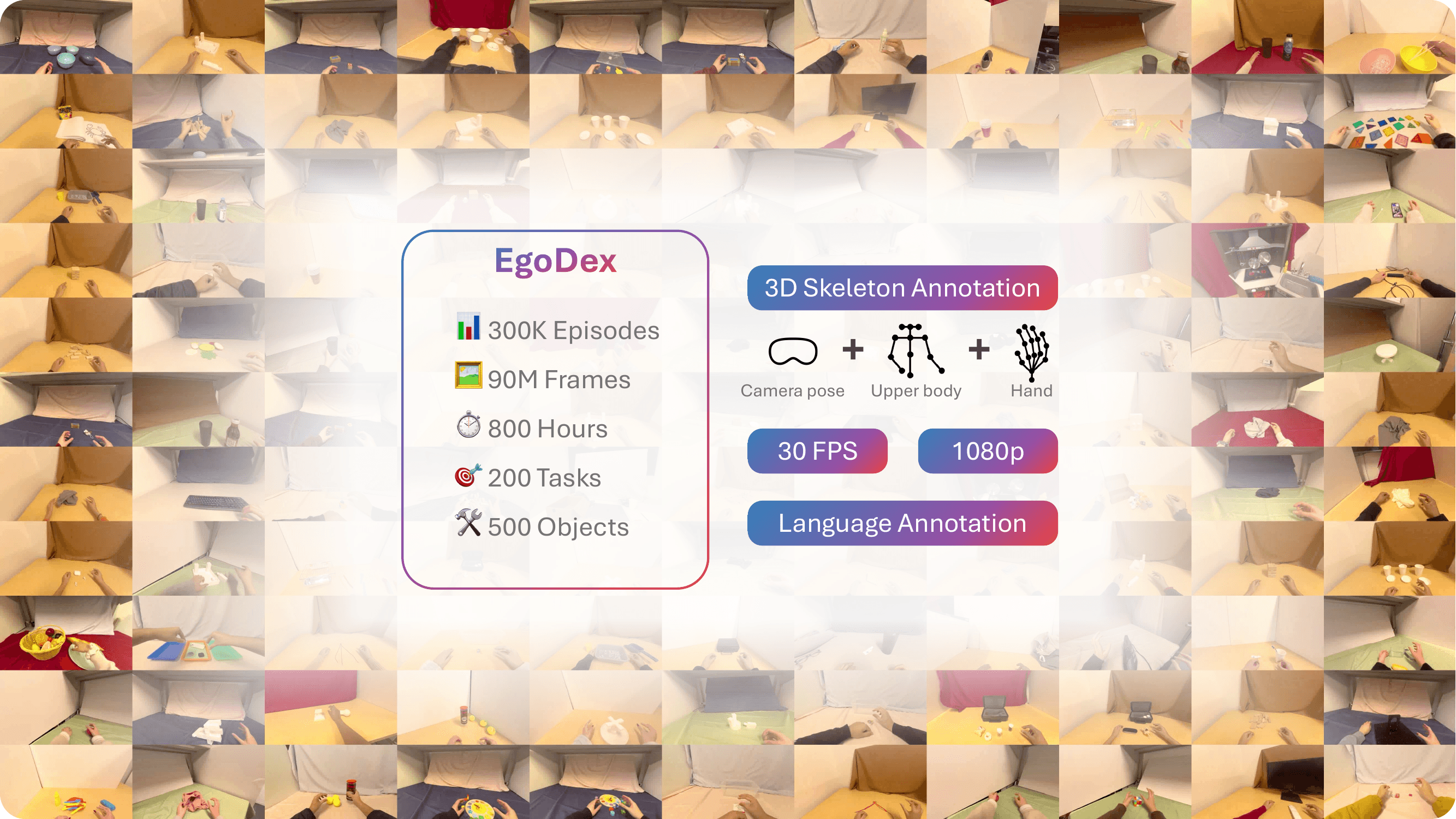
Imitation learning for manipulation has a well-known data scarcity problem. Unlike natural language and 2D computer vision, there is no Internet-scale corpus of data for dexterous manipulation. One appealing option is egocentric human video, a passively scalable data source. However, existing large-scale datasets such as Ego4D do not have native hand pose annotations and do not focus on object manipulation. To this end, we use Apple Vision Pro to collect EgoDex: the largest and most diverse dataset of dexterous human manipulation to date. EgoDex has 829 hours of egocentric video with paired 3D hand and finger tracking data collected at the time of recording, where multiple calibrated cameras and on-device SLAM can be used to precisely track the pose of every joint of each hand. The dataset covers a wide range of diverse manipulation behaviors with everyday household objects in 194 different tabletop tasks ranging from tying shoelaces to folding laundry. Furthermore, we train and systematically evaluate imitation learning policies for hand trajectory prediction on the dataset, introducing metrics and benchmarks for measuring progress in this increasingly important area. By releasing this large-scale dataset, we hope to push the frontier of robotics, computer vision, and foundation models.
*Equal Contributors
Incentivizing Temporal-Awareness in Egocentric Video Understanding Models
July 9, 2026research area Computer Vision, research area Methods and Algorithms
Multimodal large language models (MLLMs) have recently shown strong performance in visual understanding, yet they often lack temporal awareness, particularly in egocentric settings where reasoning depends on the correct ordering and evolution of events. This deficiency stems in part from training objectives that fail to explicitly reward temporal reasoning and instead rely on frame-level spatial shortcuts. To address this limitation, we propose…
MM-Ego: Towards Building Egocentric Multimodal LLMs
April 11, 2025research area Computer Vision, research area Speech and Natural Language Processingconference ICLR
This research aims to comprehensively explore building a multimodal foundation model for egocentric video understanding. To achieve this goal, we work on three fronts. First, as there is a lack of QA data for egocentric video understanding, we automatically generate 7M high-quality QA samples for egocentric videos ranging from 30 seconds to one hour long in Ego4D based on human-annotated data. This is one of the largest egocentric QA datasets…

Our research in machine learning breaks new ground every day.