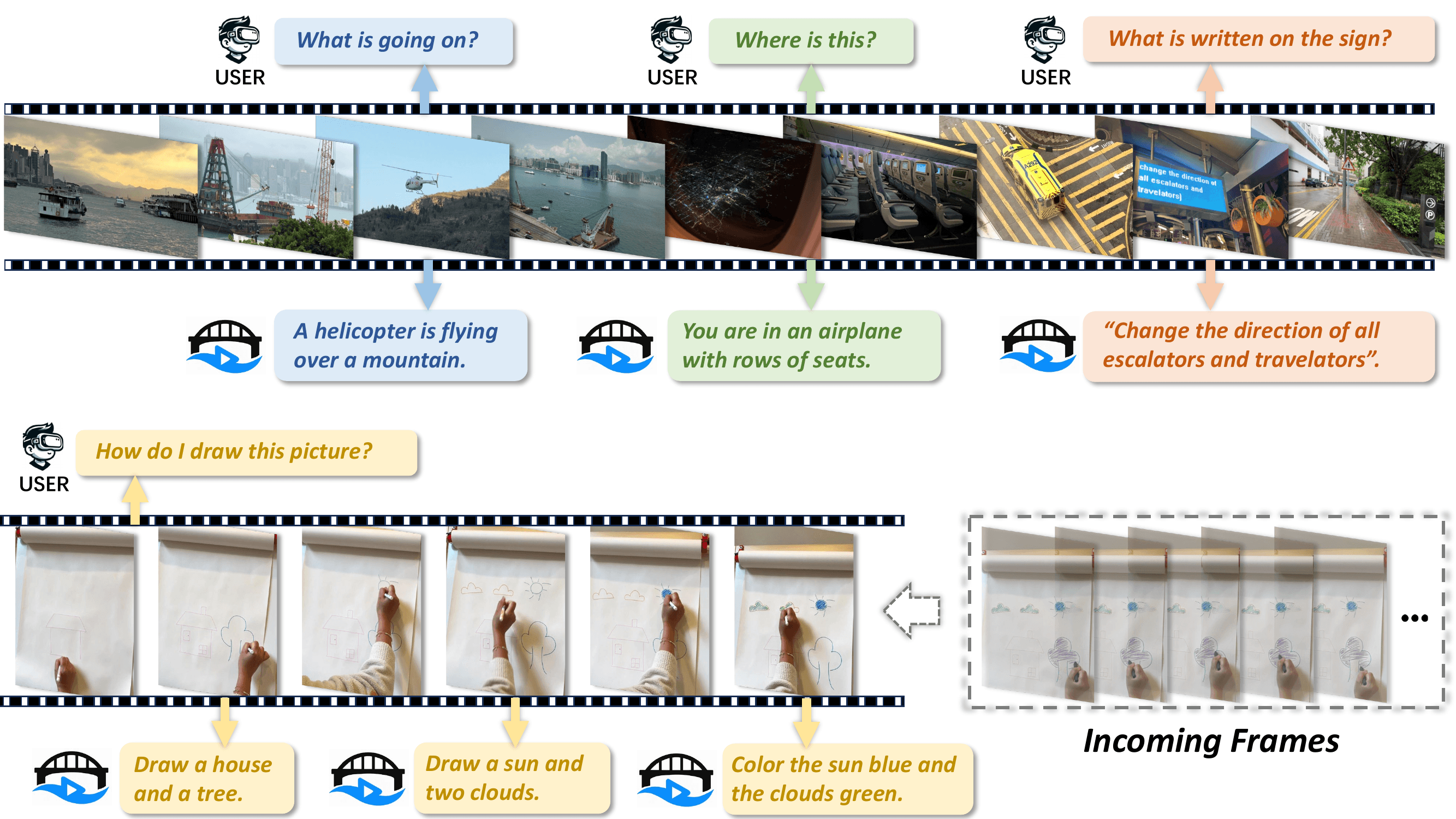
We present StreamBridge, a simple yet effective framework that seamlessly transforms offline Video-LLMs into streaming-capable models. It addresses two fundamental challenges in adapting existing models into online scenarios: (1) limited capability for multi-turn real-time understanding, and (2) lack of proactive response mechanisms. Specifically, StreamBridge incorporates (1) a memory buffer combined with a round-decayed compression strategy, supporting long-context multi-turn interactions, and (2) a decoupled, lightweight activation model that can be effortlessly integrated into existing Video-LLMs, enabling continuous proactive responses. To further support StreamBridge, we construct Stream-IT, a large-scale dataset tailored for streaming video understanding, featuring interleaved video-text sequences and diverse instruction formats. Extensive experiments show that StreamBridge significantly improves the streaming understanding capabilities of offline Video-LLMs across various tasks, outperforming even proprietary models such as GPT-4o and Gemini 1.5 Pro. Simultaneously, it achieves competitive or superior performance on standard video understanding benchmarks.
† Fudan University
‡‡ Work done during Apple internship
Streaming vision-language models (VLMs) continuously generate responses given an instruction prompt and an online stream of input frames. This is a core mechanism for real-time visual assistants. Existing VLM frameworks predominantly assess models in offline settings. In contrast, the performance of a streaming VLM depends on additional metrics beyond pure video understanding, including proactiveness, which reflects the timeliness of the model’s…
This paper was accepted at the Evaluating the Evolving LLM Lifecycle Workshop at NeurIPS 2025.
Existing video understanding benchmarks often conflate knowledge-based and purely image-based questions, rather than clearly isolating a model’s temporal reasoning ability, which is the key aspect that distinguishes video understanding from other modalities. We identify two major limitations that obscure whether higher scores truly indicate stronger…